Nous décrivons ici la version GPU de la réduction de somme avec la librairie OpenCL-1.x : le but est d'obtenir la somme de tous les éléments d'un tableau 1D. Nous présenterons le Kernel Code utilisé et ferons un comparatif avec la version CPU pour différentes tailles de tableau et de Work-Group. A noter que la version OpenCL-1.x dispose de fonctions de réduction prêtes à l'emploi (basées sur la fonction atomique atom_cmpxchg) mais elles ne sont pas très performantes : celles présentes dans la version OpenCL-2.x offriront une meilleure optimisation. Ce qui suit est donc un exemple pédagogique qui permet de mieux comprendre la manière de paralléliser un code avec toutes les fonctionnalités qu'offre l'API OpenCL. Les sources du programme sont disponibles sur le lien suivant :
Pour compiler, taper "make" puis lancer l'exécutable "sumReductionGPU" avec pour premier paramètre, la dimension du tableau, et comme second, la taille du Work-Group.
Le Kernel code dans OpenCL est le coeur du traitement parallèle d'un programme GPU. C'est lui qui réalise la majeure partie du gain de performances comparée à la version séquentielle. Nous rapellons que dans l'architecture d'un programme OpenCL, le traitement est divisé en Work-Group et pour chacun de ces sous-ensembles, les variables déclarées en local sont partagées par tous les threads du Work-Group : on parle alors de mémoire locale par opposition à la mémoire globale qui fait référence aux Work-Items, c'est-à-dire au nombre total d'appels du Kernel code, chacun représentant un processus.
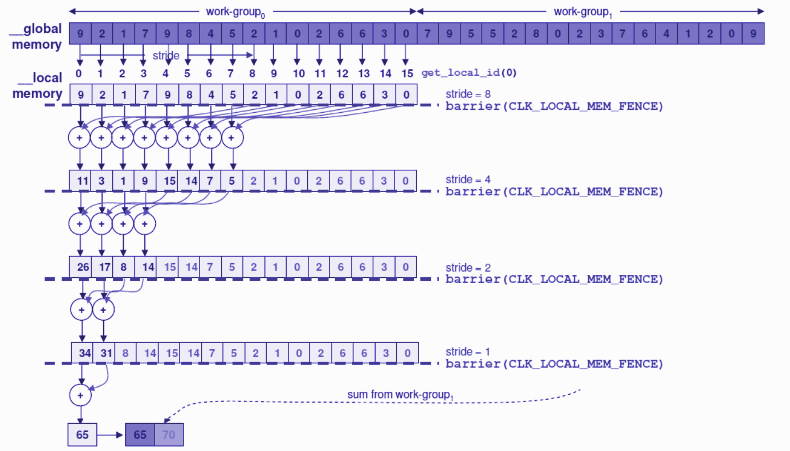
La stratégie consiste à bénéficier de la copie dans la mémoire locale de toutes les valeurs d'un même Work-Group. Celui-ci est alors divisé en 2 parties (de taille "stride") et nous ajoutons les éléments 2 à 2 avec un décalage égal à la valeur "stride". Puis nous réitérons cette opération après avoir divisé à nouveau le sous-tableau par 2. L'opération s'arrête quand nous atteignons une valeur pour "stride" inférieure à 1. Cet algorithme est illustré par la figure ci-dessous :
Il est nécessaire, à l'intérieur d'un Work-Group, de synchroniser tous les threads qui y sont associés. En effet, avant de recommencer une autre itération (c'est-à-dire une autre division par 2), nous devons nous assurer que toutes les "stride" sommes partielles ont été accomplies. Cette synchronisation de tous les processus à l'intérieur d'un Work-Group se fait grâce à l'instruction barrier(CLK_LOCAL_MEM_FENCE).
// Copy from global to local memory
localSums[local_id] = input[get_global_id(0)];
// Loop for computing localSums : divide WorkGroup into 2 parts
for (uint stride = group_size/2; stride>0; stride /=2)
{
// Waiting for each 2x2 addition into given workgroup
barrier(CLK_LOCAL_MEM_FENCE);
// Add elements 2 by 2 between local_id and local_id + stride
if (local_id < stride)
localSums[local_id] += localSums[local_id + stride];
}
// Write result into partialSums[nWorkGroups]
if (local_id == 0)
partialSums[get_group_id(0)] = localSums[0];
}
A noter qu'à la fin du traitement de calcul, nous obtenons un tableau contenant toutes les sommes partielles de chaque Work-Group. Il convient alors de faire un dernier calcul, celui de la sommation des éléments du tableau partialSums.
La sommation finale peut se faire alors par le CPU ou le GPU. Pour obtenir un meilleur gain sur le temps d'exécution, nous choisissons dans nos tests d'effectuer ce calcul final par CPU; en effet, si l'on se sert des fonctions de réduction "built-in" GPU dans le kernel (basées sur atom_cmpxchg), les performances sont nettement moins bonnes. Ceci pourra être comparé avec les fonctions atomiques de OpenCL-2.x.
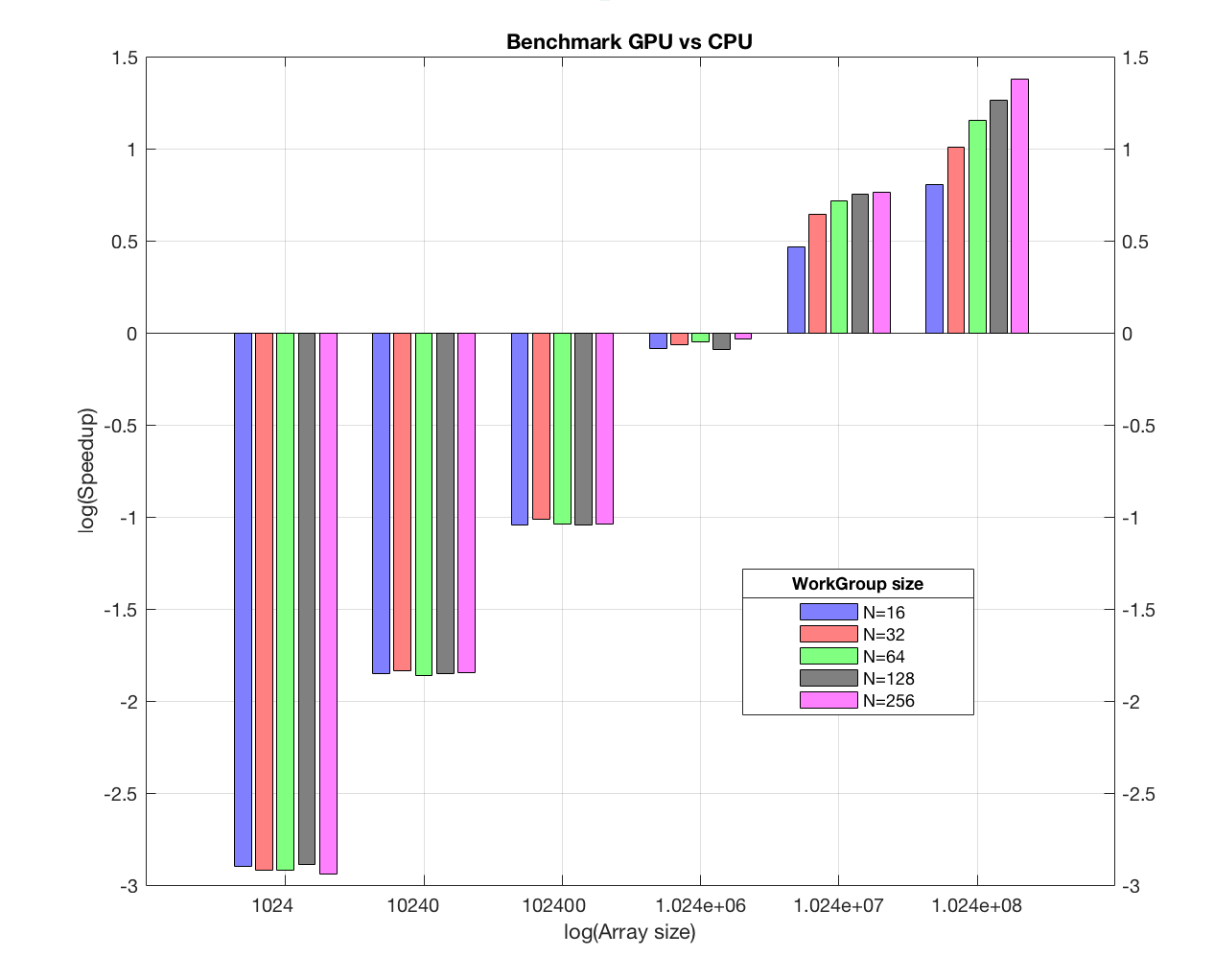
Nous faisons maintenant le comparatif des "runtime" entre la version GPU et la version séquentielle (CPU) pour différentes tailles de tableaux et de Work-Group. Ce benchmark a été réalisé avec une carte AMD Radeon HD 7970. Le Shell script run_performances_sumGPU permet de générer le fichier contenant les temps d'exécution. Voici les résultats obtenus via le source Matlab plot_performances_sumGPU.m :
Figure 1 : SpeedUp GPU vs CPU en fonction de la taille du tableau et des WorkGroup
Nous remarquons que le bénéfice de la parallélisation OpenCL est effective pour des tableaux de dimension supérieure à 1 million. Pour des speedup supérieurs à 1, on voit que les meilleurs runtime se font avec des Work-Group de taille 256. En effet, étant donné que pour ces cas-là, les dimensions des tableaux sont très importantes, nous avons intérêt à avoir un nombre de Work-Group (numWorkGroup = NworkItems/sizeWorkGroup) limité, ce qui s'obtient en prenant une taille de Work-Group maximale (ici, OpenCL nous limite à sizeWorkGroup = 4100 avec la carte GPU utilisée). Enfin, pour une taille de l'ordre de 100 Millions, nous réalisons un speedup maximal égal à 25.
Les opérations de réduction (comme la somme, la recherche de min ou de max ou encore la recherche de l'indice correspondant au min ou au max) sont utilisées fréquemment dans la conception d'algorithme. Nous nous sommes restreints dans notre cas au calcul de la réduction de somme pour une seule itération. Ceci peut s'étendre par exemple aux schémas itératifs où nous avons besoin, à l'intérieur d'une boucle principale, de calculer la somme d'un tableau modifié à chaque itération. Il faut alors appeler la fonction "clEnqueueNDRangeKernel" dans cette boucle et mettre comme argument, avec la fonction "clSetKernelArg", le tableau nouvellement calculé. Pour des dimensions assez grandes (supérieures à 1 Million), on s'attend à obtenir un gain significatif sur le temps d'exécution.
ps : contribuez comme moi au projet Cosmology@Home dont le but est d'affiner le modèle décrivant le mieux notre Univers.