En langage C, les éléments sont rangés et stockés consécutivement selon les lignes ("rows" anglais). Pour créer ce tableau 2D (ici de type double), que l'on note x0, avec un nombre de lignes égal à size_x et un nombre de colonnes égal à size_y, on effectue l'allocation d'un tableau de taille size_x*size_y dont l'adresse du premier élément se situe à x0[0]. Nous affectons ensuite à chaque élément x0[j] l'adresse du bloc correspondant au début d'une ligne. Voici la portion de code :
// Declaring double pointer for 2D array
double **x0;
Après ce morceau de code, le tableau x0 peut être initialisé car l'élément (i,j) sera accessible par la notation x0[i][j]. L'utilisation de tableaux 2D contigus en mémoire sert par exemple dans le développement d'applications MPI, où les vecteurs (lignes et colonnes) échangés doivent être contigus.
Comme dans le cas 2D ci-dessus, on va créer un tableau 3D, que l'on note x0, comportant size_x lignes, size_y colonnes et size_z pour la troisième dimension.
// Loop on rows
for (i = 0; i < size_x; i++)
{
// Allocating size_y columns for each row
x0[i] = malloc(size_y * sizeof(**x0));
// Loop on columns
for (j = 0; j < size_y; j++)
{
// Incrementing size_z block on x0[i][j] address
x0[i][j] = x0_alloc;
x0_alloc += size_z;
}
}
De la même manière que pour le cas 2D, après ce morceau de code, l'initialisation du tableau x0 peut être effectuée car l'élément (i,j,k) sera accessible par la notation x0[i][j][k]. L'utilisation de tableaux 3D contigus en mémoire sert par exemple dans le développement d'applications MPI, où l'on échange entre processus des matrices qui doivent être alignées.
On peut produire en une seule ligne de commande un flux de données que l'on va transférer à gnuplot
à l'aide d'un pipe. Voici comment faire pour tracer la fonction $y=\cos(x)$ avec $0 < x < 10$ :
seq 0 0.1 10 | gnuplot -p -e 'plot "-" u 1:(cos($1)) w l'
La commande "seq 0 0.1 10" génère une colonne de donnés comprises entre 0 et 10 avec un incrément de 0.1. On "pipe" ce flux dans gnuplot avec les options -e (gnuplot exécute les commandes passées en paramètres après cette option) et -p (le fenêtre du plot ne se ferme pas quand la commande est exécutée). Attention de bien respecter l'ordre des options -p -e.
Autre solution avec la fonction "awk" - Représentation de la fonction $y=x^{2}$ :
seq 0 0.1 10 | awk '{printf("%3f\t%3f\n", \$1, \$1^2)}' | gnuplot -p -e 'plot "-" u 1:2 w l'
Pour remplacer les virgules par des points avec les flottants dans les versions de Bash "non Anglo-saxonnes", ne pas oublier de faire : export LC_NUMERIC=en_US
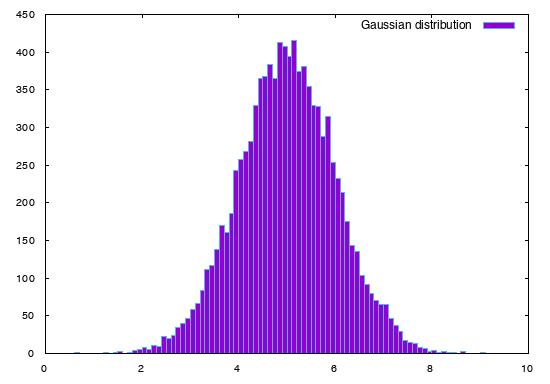
Voici un moyen rapide de générer une distribution de Gauss. Pour cela, nous utilisons le module random de python :
for ((i=1;i<=10000;i++));do python -c"import random; print \min(10,max(0,random.gauss(5,1)))";done | \
gnuplot -p-e"set terminal png size 550,384 font 'Helvetica,9'; \set tics font 'Helvetica,8'; set output 'gaussian.png'; \set style data histograms; set style histogram cluster gap 1; \set style fill solid border 3; set boxwidth 0.1; binwidth=0.1; \bin(x,width)=width*floor(x/width) + width/2.0; set xrange[0:10]; \plot '-' using (bin(\$1, binwidth)):(1) smooth frequency with boxes \title '{Gaussian distribution}'"
Voici ci-dessous la distribution obtenue avec $\mu=5$ et $\sigma=1$ :
Figure 1 : Exemple d'une distribution de Gauss(5,1) avec 10000 tirages dans un intervalle [0,10]
Si l'on veut sauvegarder les valeurs de l'histogramme dans un fichier, on doit faire :
set table 'hist.dat'; \
plot '-' using (bin(\$1, binwidth)):(1) smooth frequency with boxes; \unset table;"
Le déroulage de boucles ("unrolling loops" en anglais) est une technique d'optimisation de code qui consiste à dupliquer le corps d'une boucle afin de limiter la répétition de l'instruction de saut. Voici ci-dessous un exemple de code qui met en évidence le gain obtenu sur le runtime pour une simple boucle. Pour cela, nous incluons le code assembleur dans un source C, ce qui permet d'utiliser la fonction gettimeofday() pour mesurer le temps d'exécution passé dans cette boucle :
Tout d'abord, le code C dans lequel nous incluons du code assembleur, sans déroulage de boucles ni autres optimisations (fichier loop-without-unroll.c) :
#include <stdio.h>#include <sys/time.h>#include <unistd.h>int main ()
{
// Init sumint sum = 0;
// Number of iterationsint n = 100000000;
struct timeval tv1, tv2;
longint diff;
// Start time
gettimeofday (&tv1, NULL);
// Loop with Sparc assembly into C sourceasmvolatile ("clr %%g1\n\t""clr %%g2\n\t""mov %1, %%g1\n"// %1 = input parameter"loop:\n\t""add %%g2, 1, %%g2\n\t""subcc %%g1, 1, %%g1\n\t""bne loop\n\t""nop\n\t""mov %%g2, %0\n"// %0 = output parameter
: "=r" (sum) // output
: "r" (n) // input
: "g1", "g2"); // clobbers// End time
gettimeofday (&tv2, NULL);
// Compute runtime for loop
diff = (tv2.tv_sec - tv1.tv_sec) * 1000000L + (tv2.tv_usec - tv1.tv_usec);
// Print results
printf ("Elapsed time = %d usec\n", diff);
printf ("Sum = %ld\n", sum);
return0;
}
Remarques sur l'inclusion pour gcc de code assembleur Sparc dans un source C :
Doubler le symbole "%" devant chaque nom de registre
"%0" correspond au paramètre de sortie
"%1" correspond au paramètre d'entrée ("%2" au deuxième, "%3" au troisième, etc ...)
La syntaxe, pour faire le lien entre les variables du source C et les registres, est la suivante :
: "=r" (sum)
: "r" (n)
: "g1", "g2"
où la première ligne correspond au paramètre de sortie ("sum"), la deuxième au paramètre d'entrée ("n") et la dernière aux registres "clobbered", c'est-à-dire les registres qui seront modifiés durant l'exécution du code assembleur (ici les registres "%g1" et "%g2").
ps : contribuez comme moi au projet Cosmology@Home dont le but est d'affiner le modèle décrivant le mieux notre Univers.